k8s入门
没事做和rmb聊天的时候,因为最近确实不知道该学啥,就扯淡的时候聊到k8s,然后想了一下感觉k8s确实很行,之前菊花入职网易的时候上手的业务也是k8s部署的,云越来越成熟的情况下学一手不是坏事
入门的一大问题在于资料有一点散,加上学习不可能有实际生产环境的部署情况,官方资料也很乱,看了一大堆文档才把各个环节理清楚
环境部署推荐使用kind,用docker作为node,2c4g的机器也能轻松部署4个node的集群
名词解释
开始之前还是先把所有的名词搞懂
Kubernetes 组件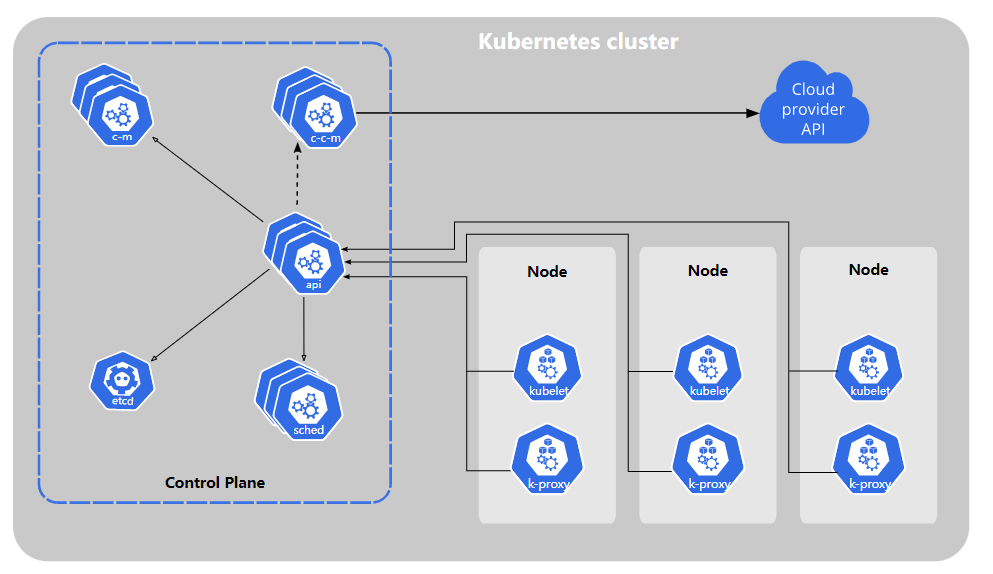
cluster
即集群,k8s的集群由多个node组成,也就是一堆可用的机器,一个集群上面可以部署各种各样不同的服务,使用kubectl cluster-info可以看到目前连接的是哪个集群,输出内容为当前集群的api server端口
node
节点,在生产环境中表现为物理机或虚拟机
节点分为两种,master节点和worker节点,master节点上运行了一系列的管理服务,负责管理整个集群。worker节点则负责打工,worker上需要装kubelet和容器运行时,前者用于和master通信,管理当前节点上运行的pod(感觉网络搭建负载均衡什么的应该也有),后者用来作为容器的运行环境,一般情况下为docker
pod
k8s中最小的资源调度单位
一个pod中可以运行多个容器(docker),同一个pod内的所以容器共享同一个网络和文件系统,但同一个node中的不同pod相互隔离,每个pod拥有一个k8s的独立内网ip,如下图
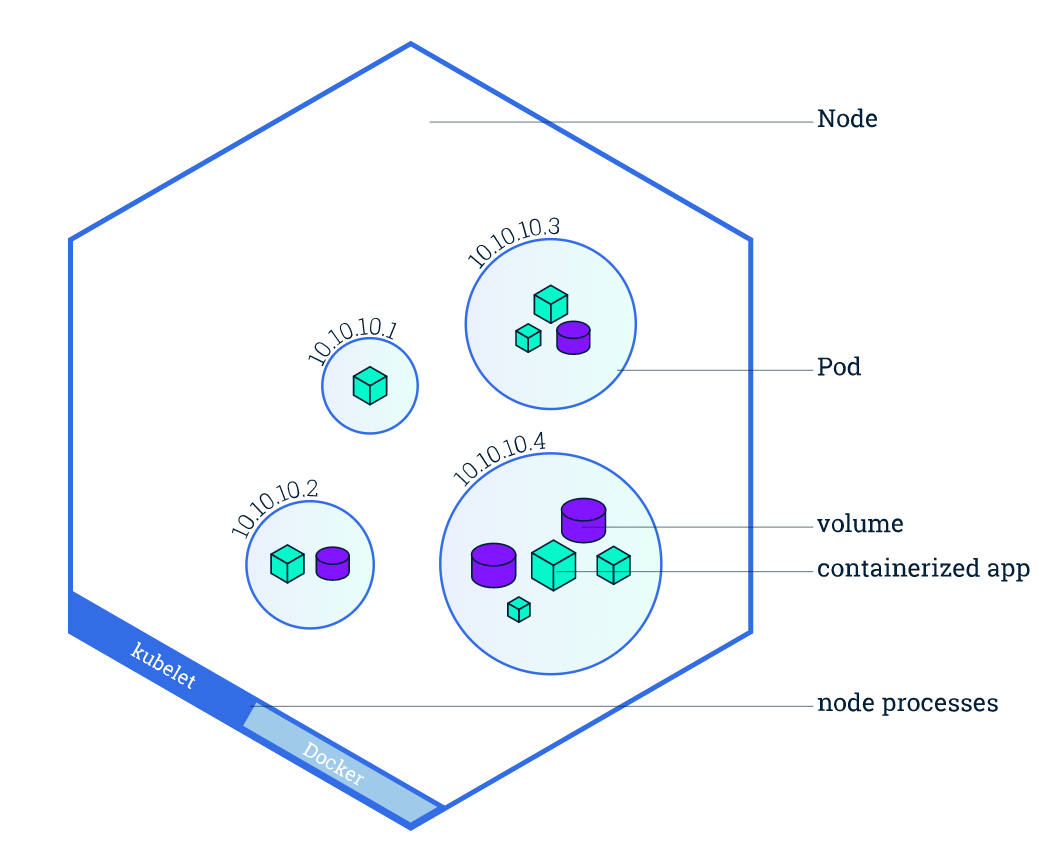
环境搭建
使用kind的话通过构造了一个能运行docker的docker,将docker作为k8s的节点,而不是物理机虚拟机,可以极大程度的节约资源,用破烂搭建起测试环境。
启动环境也很简单,写一个config.yaml,然后kind create cluster -n <cluster_name> --config config.yaml,-n指定的是cluster的名字,样例config.yaml如下
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker
启动一个一个master三个worker的集群,该命令还会在~/.kube/config中写入对应集群的配置文件。这之后就没有kind什么事了,他的功能就是快速的为我们搭建一个简易的k8s集群,虽然每个节点都是docker,但也是可以跑起来的,接下来就需要使用kubectl对集群进行操作了(kubectl需要用snap单独装一下)
也还有其他的搭建k8s集群的方案,minikube是用虚拟机作为节点搭建的,也支持一键搭,更原始的方案应该是用VMware之类的起几个虚拟机,然后上去手动装kubectl套件和docker,选择其中的一个作为master节点,然后其他的几个作为worker节点,手动连接到master加入集群
如下是ChatGPT给出的命令
kubeadm init --pod-network-cidr=<POD_CIDR>
kubeadm join <MASTER_IP>:<PORT> --token <TOKEN> --discovery-token-ca-cert-hash sha256:<CERT_HASH>
想运行自己的docker的话,kind也支持将image导入节点中,不过注意在build的时候要指定image的版本号,不要默认的latest,导入命令如下kind load docker-image <image_name> -n <cluster_name>
使用该命令查看image有没有被导入docker exec -it <container_name> crictl images
导入进去之后image会有一个docker.io/library/的前缀,导致我一开始以为没导入进去找半天
之后在k8s拉起环境的时候image处添加一项imagePullPolicy: IfNotPresent即可使用本地镜像
基本操作
各种命令有一个官方小抄
kubectl Cheat Sheet
pod
pod是k8s中最小的资源调度单位,一个pod运行一个最小的功能系统,不过实际上pod在k8s中是经常销毁和重建的,一般来说部署应用并不使用pod,官方的教程里面也没有直接创建pod
操作pod的命令倒是可以记一下
kubectl get pods
kubectl describe pods
kubectl get pods -o wide # 可以看到每个pod被部署到哪个机器上
kubectl delete pods
kubectl exec --
exec和docker exec差不多,要交互式shell的时候还需要加一个-it
deployment
正式的部署操作以deployment为主,后续的大部分操作也都是以deployment为操作单位进行的。deployment部署时可以指定部署的pod数量,以及运行的镜像。deployment会保证服务的有效性,当一个pod挂掉的时候会创建新的来补上,并且可以部署的pod上进行负载均衡等操作
kubectl create deployment --image --replicas
kubectl get deployments.apps
kubectl describe deployments.apps -n
kubectl delete deployments.apps
deployment部署的pod都会以deployment的名字开头并追加一个随机字符串,如果用delete pod删掉其中的一个,deployment就会创建一个新的来顶替他,以保证一直有replicas个数量的pod能够提供服务
replicas
可以通过如下命令手动更改副本的数量,副本并不会挂机,而是会被负载均衡进行请求分发kubectl scale deployment <deployment_name> --replicas 4
service
一层网络抽象,可以把分散在各个node上的pod暴露出来,提供服务并进行负载均衡
用deployment起了4个redis,然后用service NodePort把端口暴露出来,这里可以看一眼NodePort的表述
- ClusterIP (默认) - 在集群的内部 IP 上公开 Service 。这种类型使得 Service 只能从集群内访问。
- NodePort - 使用 NAT 在集群中每个选定 Node 的相同端口上公开 Service 。使用<NodeIP>:<NodePort> 从集群外部访问 Service。是 ClusterIP 的超集。
- LoadBalancer - 在当前云中创建一个外部负载均衡器(如果支持的话),并为 Service 分配一个固定的外部IP。是 NodePort 的超集。
- ExternalName - 通过返回带有该名称的 CNAME 记录,使用任意名称(由 spec 中的externalName指定)公开 Service。不使用代理。这种类型需要kube-dns的v1.7或更高版本。
等于说这个service对应的所有worker都会开那个端口,然后访问任意一个worker的端口都会由k8s把请求分配到一个pod上,连worker1端口写的数据并不一定会写到worker1上运行的pod中,即使worker1上没有运行pod,但只要worker1是当前deployment中可用的worker,也可以通过连接worker1上对应的端口来访问pod
试了一下写数据,实测证明这个并不会同步,随机连上去写一个pod,再次访问连上的pod不一定有这个数据
service用官方文档的这个图解释就很好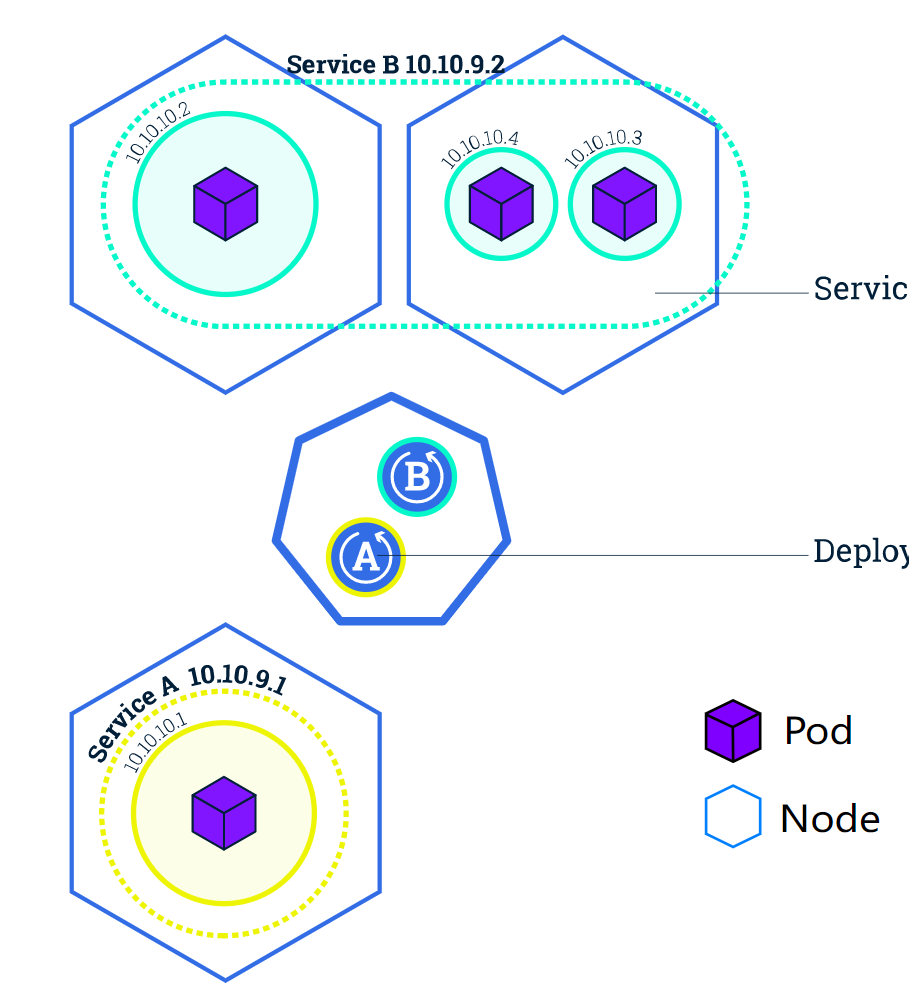
首先每个pod在k8s集群中有自己的ip,service将所有的pod打一个包,以一个ip暴露出来,就是ClusterIP的形式,而选用NodePort形式,则将每个node的对应端口再暴露一层,但实际上访问node的端口,最后会转发到service上,再分配给每个pod。有了service的包裹,所有对pod的访问全都在service层面接受再分发,使得单个pod的销毁和新建都不会影响服务的稳定性
Service 通过一组 Pod 路由通信。Service 是一种抽象,它允许 Pod 死亡并在 Kubernetes 中复制,而不会影响应用程序。在依赖的 Pod (如应用程序中的前端和后端组件)之间进行发现和路由是由Kubernetes Service 处理的。
不过实际应用的时候感觉LoadBalancer会更加合理,不需要每个worker都开对应端口,只有一个负载均衡在外面接受请求。试了一下这个选项外部IP分配不出来。。。感觉正常使用情况估计是充钱云服务商会提供现成的
kind拉起的环境是可以配负载均衡的, 配出来之后可以在docker对应的网段拉出来一个LoadBalancer,在vps范围内可以访问,这里是官方教程
kind-LoadBalancer
非常好用的能够把service再暴露到kubectl所在机器的命令,可以把kind搭起来的docker k8s暴露出来了
kubectl port-forward services/<svc_name> --address 0.0.0.0 <listen_port>:<dst_port>
但是这里存在一个迷之坑点,port-forward好像会将所有的请求都分配到一个pod上,而不是原来的负载均衡情况,如果是生产环境的话负loadBalancer和NodePort就直接在公网上开放服务了,kind搭的内网环境下就体现为vps能直接访问,再套到公网的话需要一个其他的端口转发再转一道
pod更新
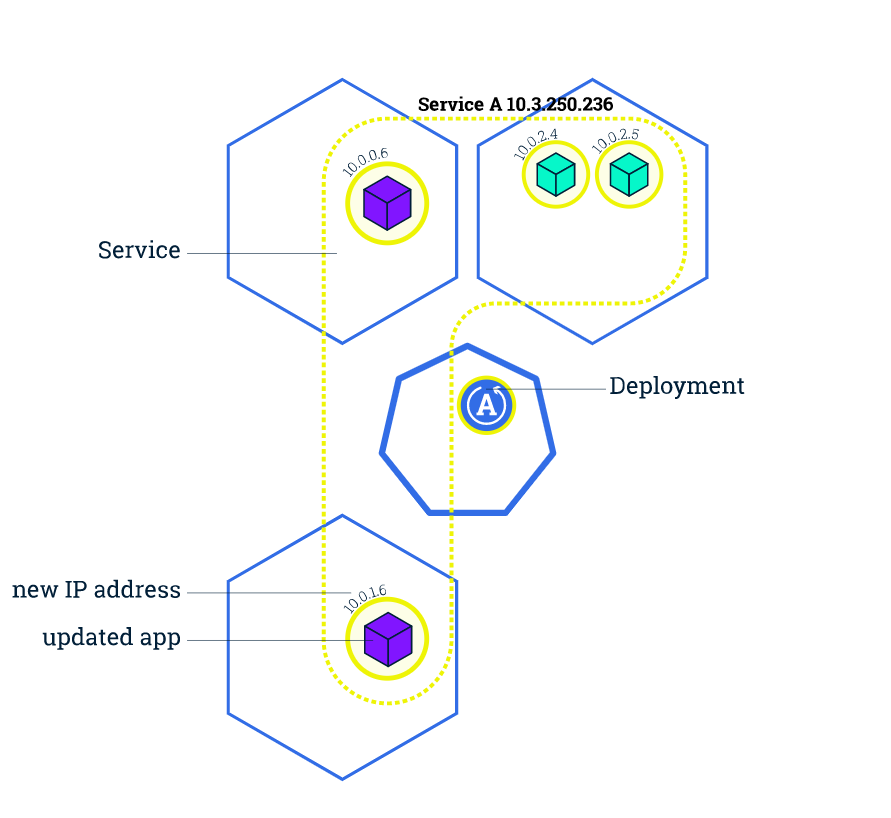
鉴于这个非常强大的负载均衡,可以对容器进行更新操作,如上图所示,对于一个多pod的deployment,更新是逐步实现的,通过逐个替换pod以实现对整个deployment的更新。默认情况下每次重启一个pod,并且就算更新跑爆了,也还能一键回滚,好人啊
不过用起来有很多注意点,命令如下
kubectl set image deployments/ =
kubectl rollout status deployments/ # 查看状态
kubectl rollout undo deployments/ # 回滚
更新时第二个参数是container name,而不是pod name,因为一个pod实际上是可以有多个container的,更新需要指定更新的是哪一个,所以需要指定的是pod里面的container
进阶操作(大概)
另分一类是因为k8s官方文档把这些操作放在基础教程的外面。。。
configMap
用来给容器添加环境变量的操作,除了configmap还有secret,不过secret默认是用base64加密的,容器在创建时可以通过如下配置以获取config
env:
- name: APP_NAME
valueFrom:
configMapKeyRef:
name: sys-app-name
key: name
如上配置从configMap中的sys-app-name表中取出name的值作为环境变量APP_NAME
env:
- name: SYSTEM_APP_USERNAME
valueFrom:
secretKeyRef:
name: sys-app-credentials
key: username
- name: SYSTEM_APP_PASSWORD
valueFrom:
secretKeyRef:
name: sys-app-credentials
key: password
上述配置则是从secret中的sys-app-credentials中取出username和password作为对应环境变量的值
配置了如上config的pod,在创建时如果没有对应的config,会出现一个CreateContainerConfigError,只有当创建了对应的配置项后才会进入ready状态
创建以及查看config/secret的命令
kubectl create configmap sys-app-name --from-literal name=my-system
kubectl create secret generic sys-app-credentials --from-literal username=bob --from-literal password=bobpwd
kubectl get configmap sys-app-name -o yaml
kubectl get secret sys-app-credentials -o yaml
可以看到secret的输出默认是base64的
官网上还有一个用configMap写配置文件的操作,不过需要注意的是,对config的更新是不会立即应用到pod上的,需要重启pod才能生效
使用 ConfigMap 来配置 Redis
volume
教程中还有一节部署无状态应用,用PHP和redis搭了一个留言板,redis三份,一份leader两份follower,不过镜像的具体实现并没有给出,就只能简单的拉起几个deployment,然后开service把端口暴露出来
有状态的应用中,提出了卷概念,可以在cluster中创建一份volume,并将其挂载在各pod的对应目录上,来实现数据的共享和持久化,解决之前说的一个pod改了其他pod不变的问题
测试的时候volume类型为hostPath,仅在pod对应的node上创建,不能在多节点中共享。可以看官方文档中卷相关节获取关于共享卷的信息
持久卷
StatefulSet
deployment的有状态版本,会在创建的时候给每个pod分配一个序列号,被销毁和调度的pod会不会像deployment一样重新拉一个随机id,而是按照之前的序列号重建,并且把原来的全套资源再恢复上去。
详解 Kubernetes StatefulSet 实现原理这篇文章里面给出了一个两个replicas的statefulset,并且给他们各自挂载了一份持久数据卷,我一开始还以为是两个共享一份,结果是两个每个一份,创建的两个pod web-0/1。尝试对web-0卷上的数据进行修改,并不会影响到web-1上的数据,但是如果将web-0销毁,重新创建的web-0会继承之前的卷,也就是保留了刚才的修改
StatefulSet主要是为了留存数据,所以其环境清理也复杂一点,直接删除statefulset是不会清理相关卷的,所以还需要单独把相关卷的声明给删掉kubectl delete persistentvolumeclaim
教程中的几个statefulSet的volume都是每个节点各自申请一份然后保证这个volume持续和对应pod绑定,并没有那种我想象中的一个volume多个节点共享以实现同步捏。。。
最后一个超长的zooKeeper教程(没有动手实践),也是每个pod挂载自己对应的volume,依靠zooKeeper自身的分布式同步功能对数据进行同步(但是我并不是很了解这个东西)
最后还提到了隔离和腾空操作,这个可以主动将一个节点腾空,要求上面的pod迁移到其他的节点上,是直接把一个机器给禁用了,在机房需要分批维护的时候应该有很大的作用
动手实践
搭了一个简单的flask app,用loadBalance负载均衡,有一个文件上传和下载功能,为了保证负载均衡后文件下载也能正常使用,还需要创建一个nfs作为持久卷,然后将nfs挂载到每个pod的上传目录
nfs server+hostPath volume
首先起一个nfs文件系统,同样使用k8s部署,但是nfs需要上privilege,nfs只需要一个,设置为stateful set,为了数据持久化,nfs server用于共享的目录也需要是一份持久卷,简单起见直接使用hostPath,绑定在对应的node上,但是一旦pod被调度,hostPath的数据就会丢失,所以还需要将pod绑定在对应的某个server上
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nfs-server
spec:
replicas: 1
selector:
matchLabels:
app: nfs-server
template:
metadata:
labels:
app: nfs-server
spec:
nodeSelector:
kubernetes.io/hostname: dev-worker
containers:
- name: nfs-server
image: itsthenetwork/nfs-server-alpine:12
imagePullPolicy: IfNotPresent
ports:
- name: nfs
containerPort: 2049
- name: mountd
containerPort: 20048
- name: rpcbind
containerPort: 111
securityContext:
privileged: true
env:
- name: SHARED_DIRECTORY
value: /nfsshare
volumeMounts:
- name: upload-data
mountPath: /nfsshare
volumeClaimTemplates:
- metadata:
name: upload-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
没有指定storageClassName,默认为standard,使用的type为hostPath,可以kubectl describe pv看一下
nfs service
其次需要将nfs server暴露出来,让其他node创建节点时可以访问到这个文件系统
一开始是按照官方的nfs example,创建一个headless service,然后直接用pod在集群内的域名访问,顶级优雅,域名格式为<podname>.<namespace>.svc.cluster.local。但是我实际用起来的时候node是无法认出这个域名的,只有集群内部的pod能够使用该域名访问,感觉都是过的kube proxy对集群内部的网络进行处理,但是node本身执行这些命令是不会过proxy的,就跑不起来,一开始不知道什么情况乱按测试浪费了一晚上。。。最后看到了一个和我一模一样情况的issue,NFS example with a cluster local service name only works on GKE but not for minikube/kubeadm,似乎是云服务的玄幻生产环境下可以用,自己部署的环境就用不了捏
最后也是套了一个loadBalancer把nfs暴露出来,NodePort也行,但是都是暴露到公网,并且使用ip访问,还需要手动配置,都不如这个集群内域名优雅
制备pv/pvc
pod使用持久卷似乎都需要通过pvc声明占有,然后pvc再去找对应的pv使用。这里有一点抽象,就是那个storageClass,好像能乱写名字?只要pv和pvc的能对应上就行,然后制备pv的时候在属性里面手动配置对应类中的字段即可。。。反正昨天问chatgpt给了我一堆垃圾回答,不能信。。。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-volume
spec:
storageClassName: "nfs"
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
nfs:
server: 172.18.255.201
#server: nfs-server.default.svc.cluster.local
path: "/"
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-claim
spec:
volumeName: nfs-volume
storageClassName: "nfs"
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
这里应该是静态制备,就先搓一个pv然后pvc靠storageClassName对上了,手写一个配置好的storageClass配好nfs相关属性,可能就可以不声明pv,直接用这个class自动创建pv了
如果管理员所创建的所有静态 PV 卷都无法与用户的 PersistentVolumeClaim 匹配, 集群可以尝试为该 PVC 申领动态制备一个存储卷。 这一制备操作是基于 StorageClass 来实现的:PVC 申领必须请求某个 存储类, 同时集群管理员必须已经创建并配置了该类,这样动态制备卷的动作才会发生。 如果 PVC 申领指定存储类为 “”,则相当于为自身禁止使用动态制备的卷。
还可以看一下这个
k8s中的PV和PVC理解
app deployment
上述操作完成之后就可以部署app了
用的自己写的一个flask app,再起一个loadBalancer给他暴露出公网即可
这里可以考虑使用initContainer对nfs服务进行等待之类的
apiVersion: apps/v1
kind: Deployment
metadata:
name: flask-app
spec:
replicas: 6
selector:
matchLabels:
app: flask-app
template:
metadata:
labels:
app: flask-app
spec:
containers:
- name: flask-app
image: docker.io/library/flask_app:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "200m"
volumeMounts:
- mountPath: /app/upload
name: nfs-volume
volumes:
- name: nfs-volume
persistentVolumeClaim:
claimName: nfs-claim
跑起来的app共享同一个上传目录,负载均衡下上传的所有文件都能进行共享
end
感觉,上手之后不是很难,对着把命令都按一遍多操作几次就有一定的基础认知了,kind强力推荐,用docker起环境真的很节约资源,低配置下也能搭起来一个节点数还可以的集群,快进到扩展阅读容器安全
neargle/my-re0-k8s-security